Hur man skapar en bra MCP server för dokumentationssidor
Vad är en MCP server?
Den bästa förklaringen får man nog om man läser direkt från den officiella dokumentationen men jag ska försöka ge min egna kortfattade version.
MCP-protokollet är ett standardiserat sätt för en MCP-kompatibel AI Agent (till exempel chatten i Cursor eller Claude) att hämta in extra kontext från en extern server, istället för att gissa sig fram baserat på vad den har lärt sig under träningen av modellen.
Rent konkret ger du då LLM-agenten en möjlighet att ställa flera frågor på egen hand till det här externa systemet, utan att behöva involvera dig. För att kunna erbjuda den här informationen måste du implementera en MCP server, som alltså implementerar det här protokollet. Några MCP servrar stödjer bara "läsning", medans andra faktiskt också stödjer skrivning och alltså kan göra saker som att lägga till ny information i en databas, skicka iväg ett meddelande på Slack eller vad som helst egentligen.
Idag ska vi bara fokusera på MCP servrar som bara stödjer läsning (read-only).
När gör MCP servern mer skada än nytta?
Ett vanligt misstag när du först börjar använda MCP servrar är att du bara sätter igång allihopa. Beroende på vilken MCP server du använder, kan du plötsligt ha fyllt upp stora delar av kontext-fönstret med massa information om verktyg med mera som bara stjäl av den dyrbara men begränsade kontexten som agenten har tillgänglig. Resultatet blir då tvärt emot det du försökte, då din agent skulle bli bättre men faktiskt blev sämre.
En bra MCP server
En MCP server som inte har det här problemet är den som Hashicorp har tillgängliggjort för terraforms dokumentation. Den har andra funktioner, men jag är mest intresserad av hur de har klarat å packa in all dokumentation om alla möjliga resurser utan att fullständigt spränga min agents kontext. Detta var extra intressant då jag själv har tänkt lite på hur man kan tillgängliggjöra dokumentation på ett effektivt sätt. En naiv tillnärmning hade varit att bara dumpa absolut all information i en väldigt tråkig men LLM-kompatibel markdown sida, lite som vi gjort på Snøkams hemsida (dette är för övrigt enligt llms.txt standarden). Detta gör dock att vi snabbt hamnar i den fallgruvan där vi bara fyller hela agentens kontekst med onödig information som inte är precis det den behöver. Men Hashicorp har gjort något smartare, och det är det vi ska se lite närmare på i den här bloggposten.
Hur studerar vi en MCP server
För att kunna inspektera en MCP server, så är det smart att använda MCP Inspector. Det här verktyget ger dig ett GUI som gör det lätt att se hur en MCP server presenterar sig för en potentiell klient. Du kan starta programmet såhär:
# Förutsätter att du har npx installeratnpx @modelcontextprotocol/inspector
När den kör, kan vi också skriva in kommandona som ska till för att koppla sig till terraforms MCP server:
Nu ser vi alltså vad en LLM-agent ser när den kopplar sig till.
Så vad är det som gör terraforms MCP server så effektiv?
Först och främst så ser vi att den exponerar ett "verktyg" eller "tool" som heter search_providers

Om vi ser lite närmare på verktygets beskrivelse, så kan vi läsa
This tool retrieves a list of potential documents based on the 'service_slug' and 'provider_document_type' provided.You MUST call this function before 'get_provider_details' to obtain a valid tfprovider-compatible 'provider_doc_id'.Use the most relevant single word as the search query for 'service_slug', if unsure about the 'service_slug', use the 'provider_name' for its value.When selecting the best match, consider the following: - Title similarity to the query - Category relevanceReturn the selected 'provider_doc_id' and explain your choice.If there are multiple good matches, mention this but proceed with the most relevant one.
Okej, så LLM-agenten förstår nog att det här verktyget ska anropas först. Den har också några parametrar:
- provider_document_type:The type of the document to retrieve,for general overview of the provider use 'overview',for guidance on upgrading a provider or custom configuration information use 'guides',for deploying resources use 'resources', for reading pre-deployed resources use 'data-sources',for functions use 'functions',for Terraform actions use 'actions',for listing resources using Terraform Search use 'list-resources'- provider_nameThe name of the Terraform provider to perform the read or deployment operation- provider_namespace# The publisher of the Terraform provider, typically the name of the company, or their GitHub organization name that created the provider- provider_version# The version of the Terraform provider to retrieve in the format 'x.y.z', or 'latest' to get the latest version- service_slugThe slug of the service you want to deploy or read using the Terraform provider, prefer using a single word, use underscores for multiple words and if unsure about the service_slug, use the provider_name for its value
Jag tolkar service_slug som någon sorts fuzzy-search term som kan användas. Så ett typiskt anrop till den här hade då blivit:
{"provider_document_type": "resources","provider_name":"azurerm","provider_namespace":"hashicorp","provider_version":"latest","service_slug":"storage_account"}
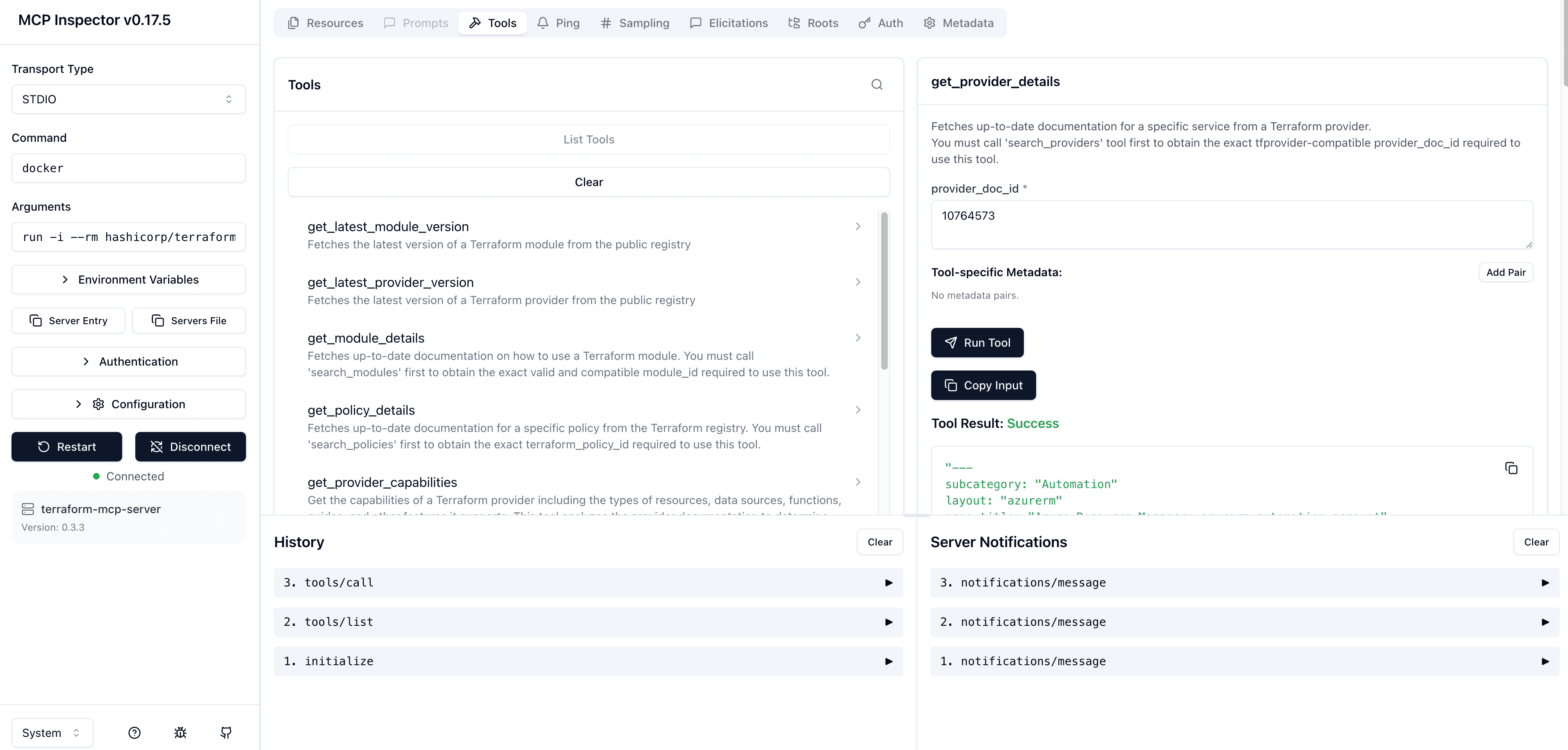
Om vi nu, i MCP Inspector, kör det här verktyget så kan vi förvänta oss något sorts svar. När jag gjorde det, så får vi tillbaka dethär:
"Available Documentation (top matches) for resources in Terraform provider hashicorp/azurerm version: 4.56.0Each result includes:- providerDocID: tfprovider-compatible identifier- Title: Service or resource name- Category: Type of document- Description: Brief summary of the documentFor best results, select libraries based on the service_slug match and category of information requested.---- providerDocID: 10834029- Title: backup_container_storage_account- Category: resources- Description: Manages a storage account container in an Azure Recovery Vault---- providerDocID: 10834372- Title: key_vault_managed_storage_account- Category: resources- Description: Manages a Key Vault Managed Storage Account.---- providerDocID: 10834373- Title: key_vault_managed_storage_account_sas_token_definition- Category: resources- Description: Manages a Key Vault Managed Storage Account SAS Definition.---- providerDocID: 10834420- Title: log_analytics_linked_storage_account- Category: resources- Description: Manages a Log Analytics Linked Storage Account.---- providerDocID: 10834842- Title: storage_account- Category: resources- Description: Manages a Azure Storage Account.---.... Det var några fler resurser här som jag skippade
Så vi kan se att söket returnerade lite intressant information som LLMn kan använda på nästa fråga, när den då kanske förstår att den skal använda get_provider_details, som i sin tur har den här beskrivningen
Fetches up-to-date documentation for a specific service from a Terraform provider.You must call 'search_providers' tool first to obtain the exact tfprovider-compatible provider_doc_id required to use this tool.
Den accepterar också en parameter provider_doc_id med beskrivningen
Exact tfprovider-compatible provider_doc_id, (e.g., '8894603', '8906901') retrieved from 'search_providers'
Nu borde det vara uppenbart för LLM-agenten att den kan anropa det här verktyget i nästa steg, med "providerDocsIDs" som den fick i första anropet i search_providers steget. Låt oss anropa det verktyget med providerDocID=10834842 och se vad vi får tillbaka:
"---subcategory: "Storage"layout: "azurerm"page_title: "Azure Resource Manager: azurerm_storage_account"description: |-Manages a Azure Storage Account.---# azurerm_storage_accountManages an Azure Storage Account.## Example Usage```hclresource "azurerm_resource_group" "example" {name = "example-resources"location = "West Europe"}resource "azurerm_storage_account" "example" {name = "storageaccountname"resource_group_name = azurerm_resource_group.example.namelocation = azurerm_resource_group.example.locationaccount_tier = "Standard"account_replication_type = "GRS"tags = {environment = "staging"}}```#... Ännu mer information här som jag inte tog med
Nice! Så LLM-agenten fick nu den fullständiga, väldigt precisa dokumentationen som beskriver hur den skall konfigurera ett Azure Storage Account i terraform, precis samma information som vi hittar här, i den officiella dokumentation för terraform providers/resurser.
Uppsummering
Vi kan alltså se exakt hur det här fungerar. Just den här MCP servern är implementerad efter ett search_provider -> get_provider_details mönster. Samtidigt är varje "entitet" i hashicorps dokumentation associerad med ett visst ID. LLM-agenten kan då snabbt kasta bort irrelevant information genom att söka med fuzzy-search, och sen utifrån den konteksten den har från kodbasen du faktiskt jobba i förstå vilken av de returnerade resurserna den skall fortsätta fråga efter. Genom att använda det här mönstret så borde man kunna effektivisera egen dokumentation också.
Om du har någon intern eller extern dokumentation som kan vara användbar för någon utvecklare som använder till exempel Cursor när den skall integrera mot ditt system, så kan detta absolut vara något att investera lite tid i.
Det var allt för den här gången! Om du har några tankar om det här eller har gjort något liknande, tveka inte att höra av dig på hei@snokam.no för att dela tips eller tricks.